Harvest Hub is a small web app my team and I built during a 24 hour hackathon. People can list extra food, people nearby can quietly claim it, and after pickup we run a simple image check that compares the “before” and “after” photos using Supabase Storage and an OpenAI.
Team: Jadyn Worthington · Joseph Caballero · Dean Walston · Mercedes Mathews
The goal was simple: move real food to real people and keep the system honest without a lot of manual oversight.
The app is built with Next.js, React, and TypeScript so the UI and APIs live in the same codebase. Supabase handles auth, Postgres, and private file storage. A single Next.js API route calls an OpenAI vision model to score how similar two images are.
Tailwind CSS keeps layout and spacing fast to work with. shadcn ui gives us solid, accessible components, and lucide-react provides the icons. It is a small stack, but it let us get to “usable” quickly.
Everything is deployed on Vercel, which runs both the Next.js pages and the API routes in one deployment.
The hackathon opened with three prompts: health advocacy, financial literacy, and food scarcity. We picked food scarcity and decided that if we were going to stay up all night, we wanted something that actually moved data end to end, not just a slide deck.
After the kickoff, we worked from about 11 PM to 8 AM building the core loop:
One stack for pages and backend code meant less setup and more time shipping features. File based routing gave us quick pages for listings and claims, and API routes let us keep all our logic close to the UI.
Supabase gave us auth, Postgres, and file storage with a single client. We created basic tables for publishers, listings, claims, and image_verifications.
Images live in a private bucket. The server generates short lived signed URLs whenever the verification route needs to read them, so we never expose bucket keys to the browser.
For verification, we send the original listing image and the proof image to an OpenAI endpoint and use the similarity score it returns. If the score is high enough, the claim is marked verified; otherwise it is flagged. It is not perfect, but it was enough to show the idea working.
We used shadcn ui for forms, cards, and modals, and lucide for icons. Those libraries let us keep the interface clean without sinking hours into custom styling also using Framer gave good animations for ladning page.
At a high level:
/api/listings, /api/claims, and /api/verify.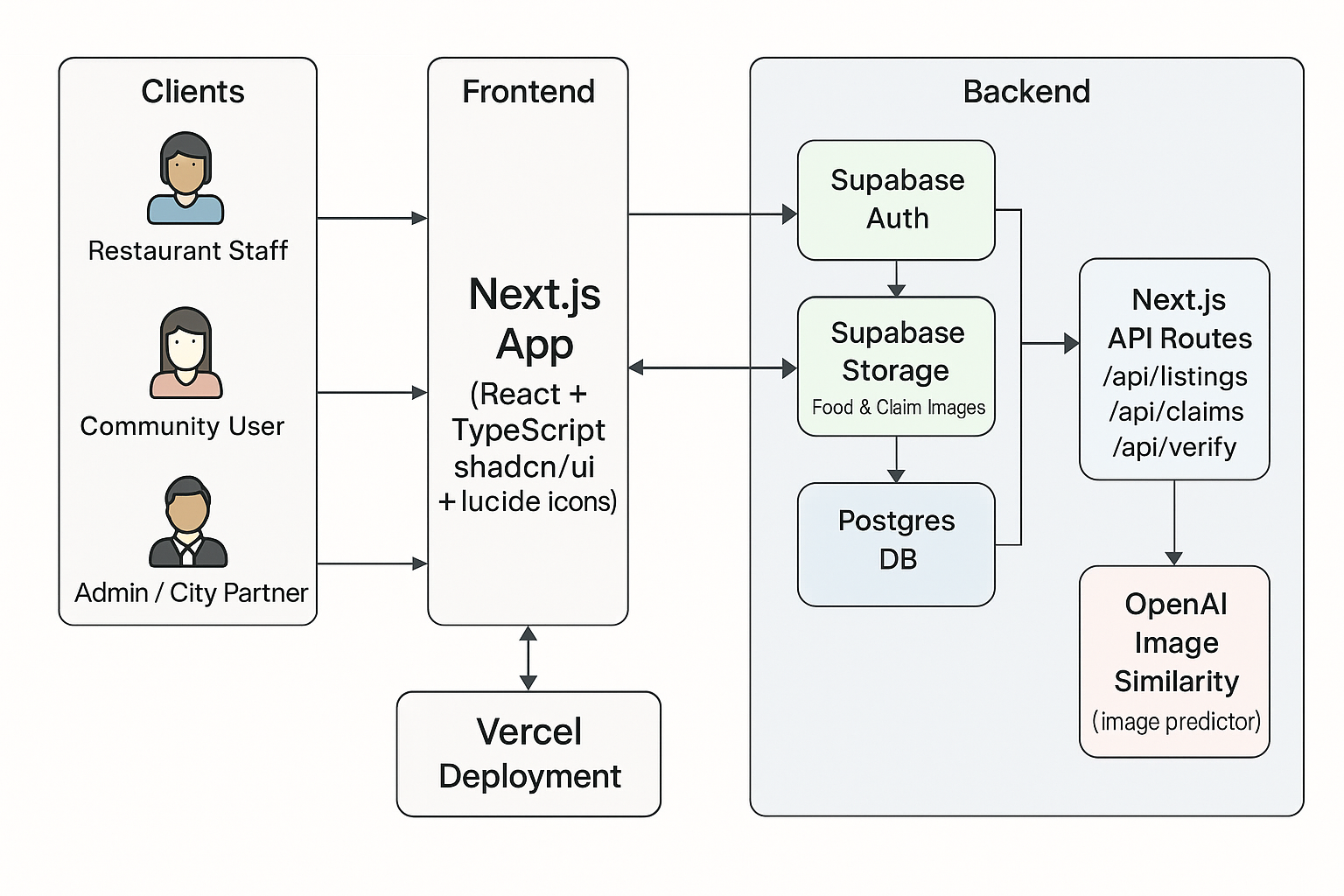
The route receives the listing form and image, uploads the image to a private bucket, and creates a row in listings with the image path and pickup window.
When a user claims a listing, we insert a row in claims with status set to pending. This records intent but does not count as a finished pickup yet.
After pickup, the user uploads a proof photo. The route stores that image, fetches both image paths, generates signed URLs, and calls the OpenAI model.
We store the score in image_verifications and update the claim to verified or flagged depending on the threshold.
The Next.js app runs on Vercel and talks to Supabase and OpenAI only through server side API routes. Writes for listings, claims, and verifications all go through those routes, which keeps the database and storage in sync. Photos are only accessible via signed URLs, and the OpenAI API key never leaves the server.
In short: Client → API routes → Supabase + OpenAI.
We did not have time for a full fraud system. A single similarity score and threshold felt like the right balance between something the judges could understand and something we could actually build that night.
Most of the debugging time was spent on getting uploads into the right bucket, storing the paths correctly, and generating signed URLs only on the server.
By agreeing on the shape of POST /api/listings, POST /api/claims, and POST /api/verify early, we were able to split the work between backend wiring and frontend flows without blocking each other.
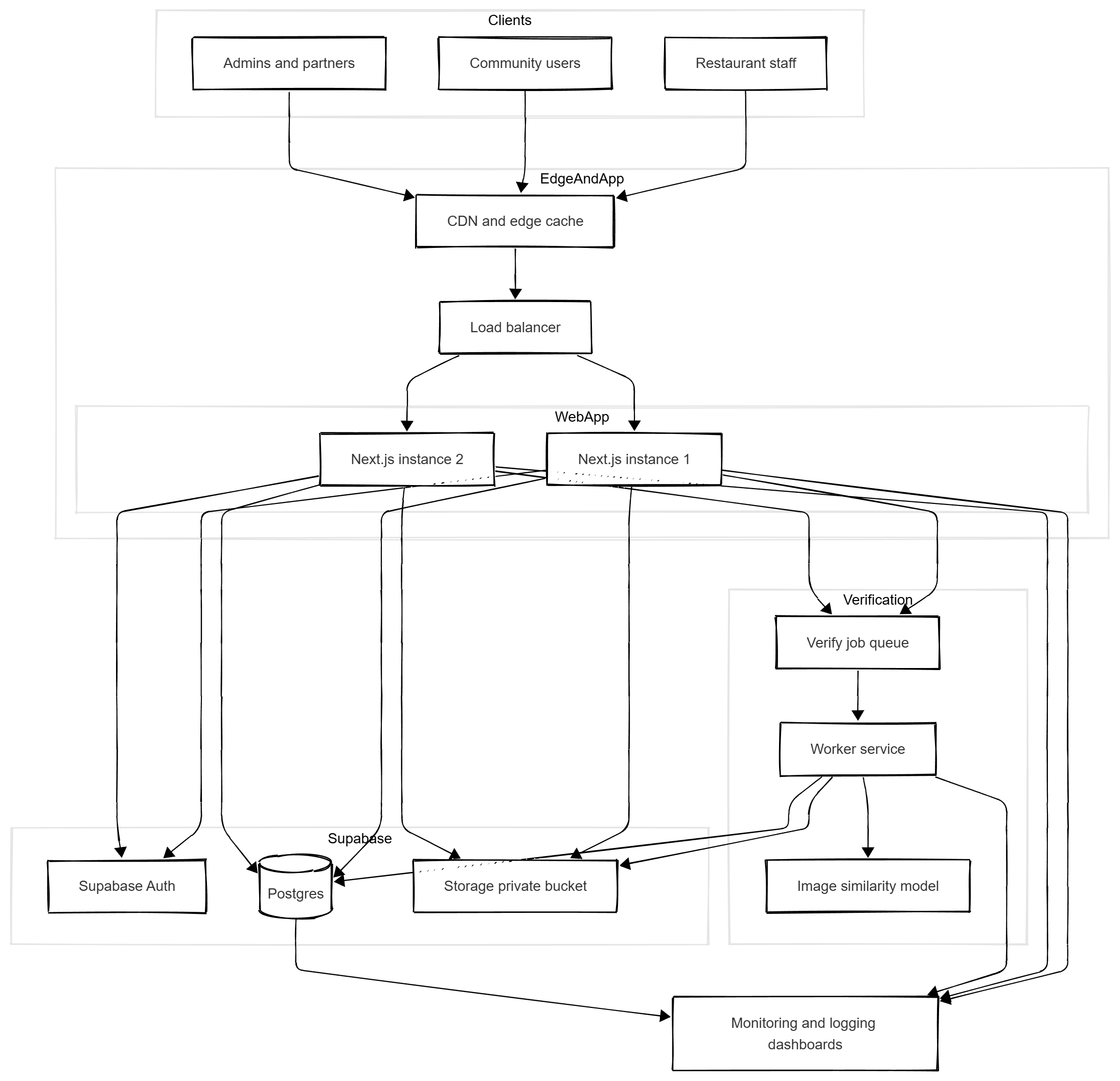
The current build is a one night hackathon project, but the shape of the system can handle real traffic with a few deliberate upgrades. The target in my head is something like one hundred thousand users and around one million reads per day.
I would keep Next.js but put it behind a CDN and a load balancer. Public listing pages are a good fit for edge caching so most read traffic never hits the app directly. The app itself would run as a few different Next.js instances that share the same environment and talk to the same Supabase project. Read endpoints are tuned to be cache friendly. Write endpoints stay small and transactional so each request either succeeds or fails clearly.
On the Supabase side the work is mostly about discipline. I would add targeted indexes on listings, claims, and verification tables that match how the UI actually queries them. Verification rows can stay append only and analytics can read from materialized views or a small reporting table so heavy dashboards do not compete with core traffic. Storage already scales well for images, so the main concern is keeping bucket paths predictable and signed URL lifetimes reasonable.
The main change to the core loop would be verification. Right now the verify route calls the model directly. At scale I would turn that into a job.POST /api/verify would write a job into a queue and return quickly. A small worker service should pull jobs, fetch signed URLs from Supabase Storage, then call the vision model, and then write the score and status back into Postgres.
In terms of CAP theorem, the internet will always give you network partitions at some point, so the real choice is how much consistency you are willing to trade for availability. For Harvest Hub I would be more towards being available: people should still be able to see listings and claim food even if a replica or the worker is having a bad day.
That means core writes like creating a listing or a claim stay strongly consistent, but secondary views are allowed to be consistent. A dashboard might be a few seconds behind. A verification status might take a small delay to flip from pending to verified. That is an acceptable trade if it keeps the app responsive in my opinion.
On top of that I would add edge caching for read heavy endpoints, rate limits on claim and verify routes.
The overall shape of the system stays the same: Next.js at the edge, Supabase as the main backend, and an async verification service on the side. The difference is that each piece is treated as something people rely on every day, not just something that has to survive a demo.